Explore
Explore and curate your data with ease across all teams
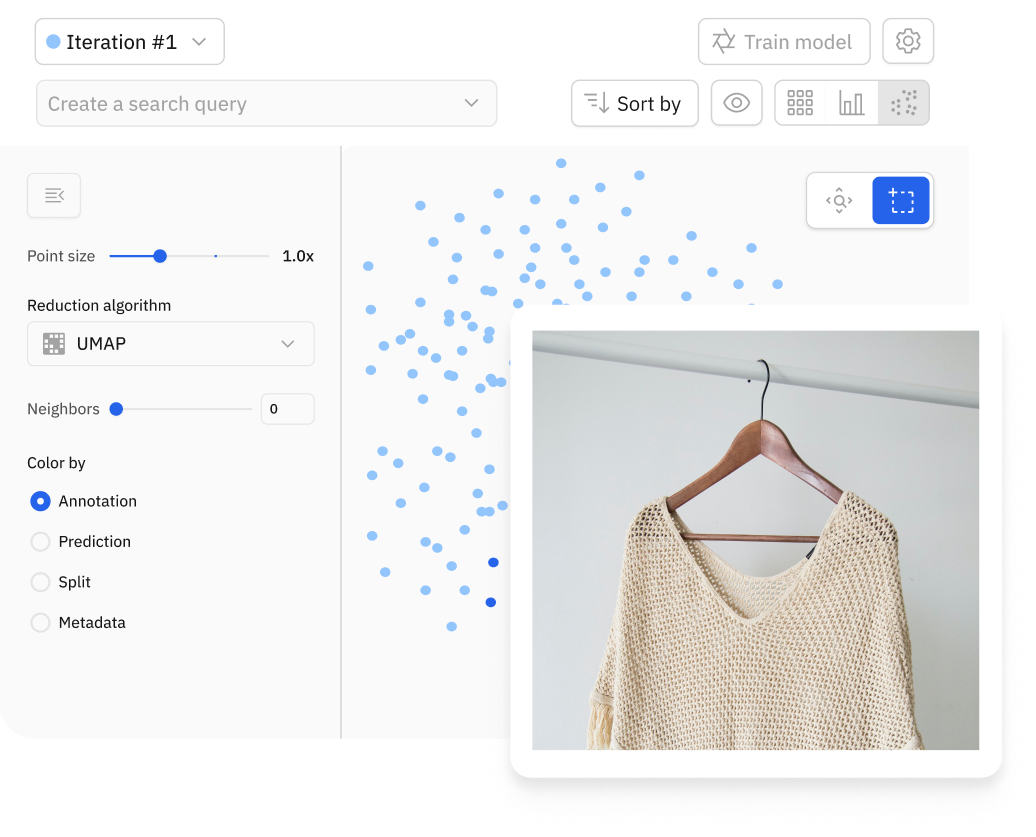
Leverage powerful vector and similarity searches
Automatically find, group, and take action on data of interest:
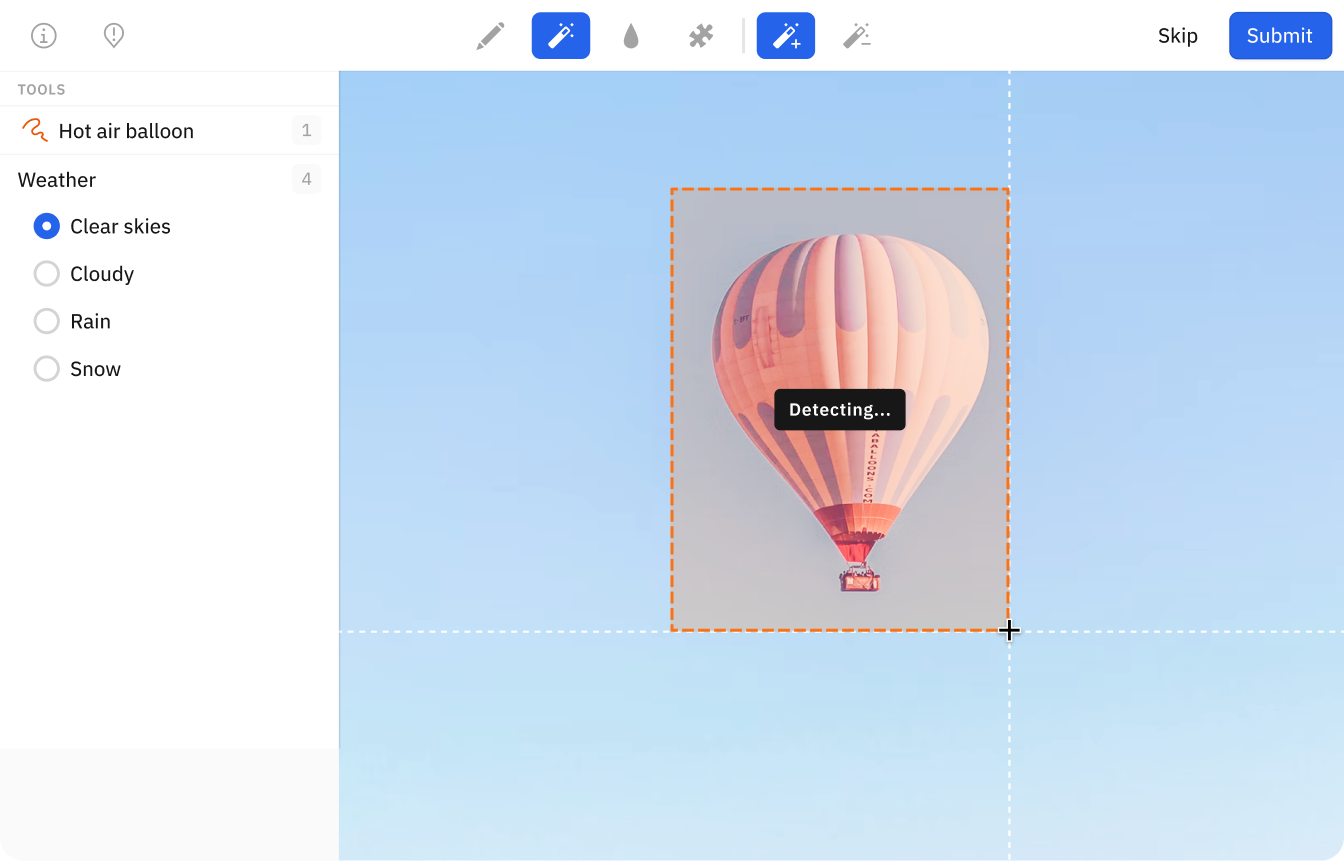
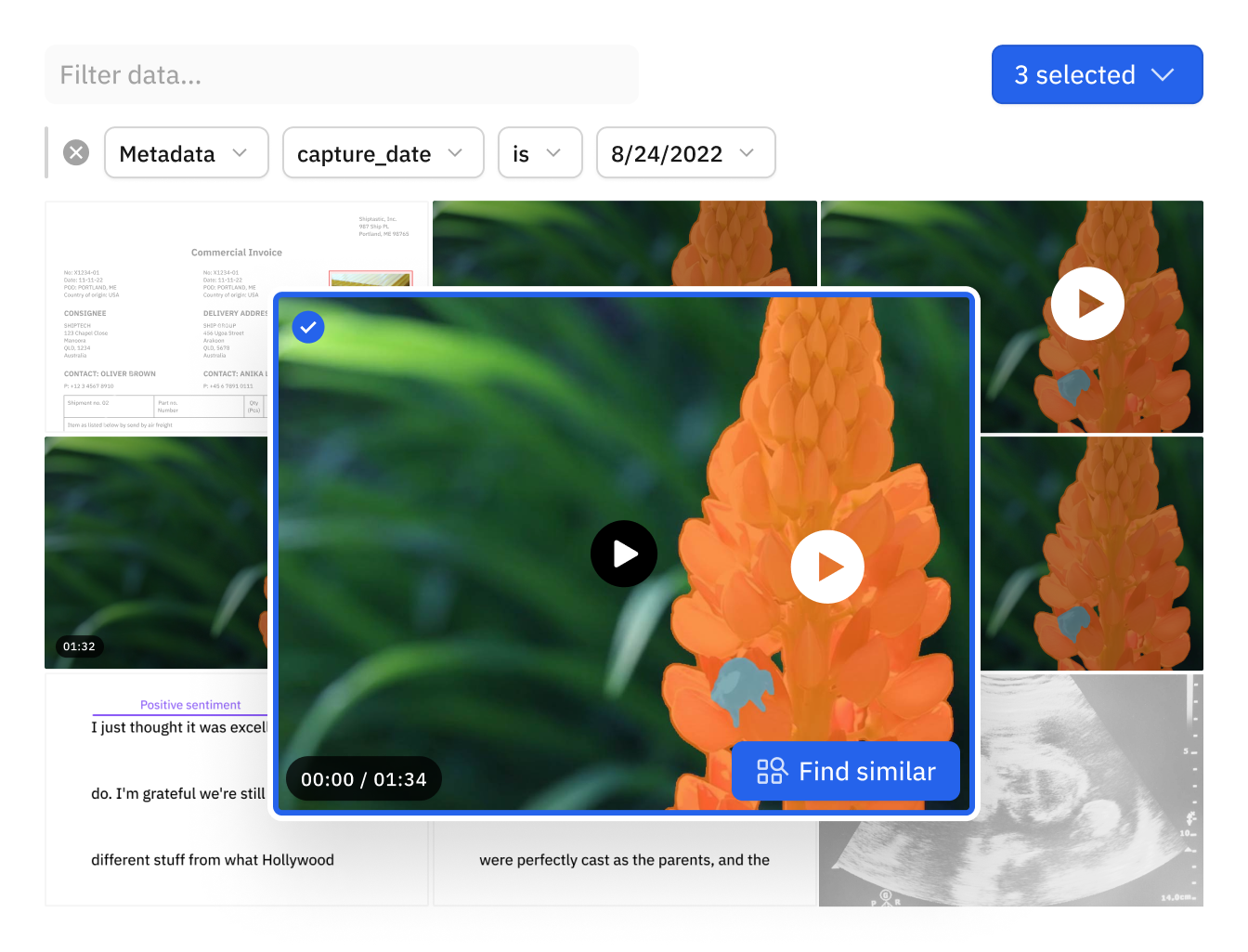
Use a vector search, such as a natural language or similarity search, to surface specific data
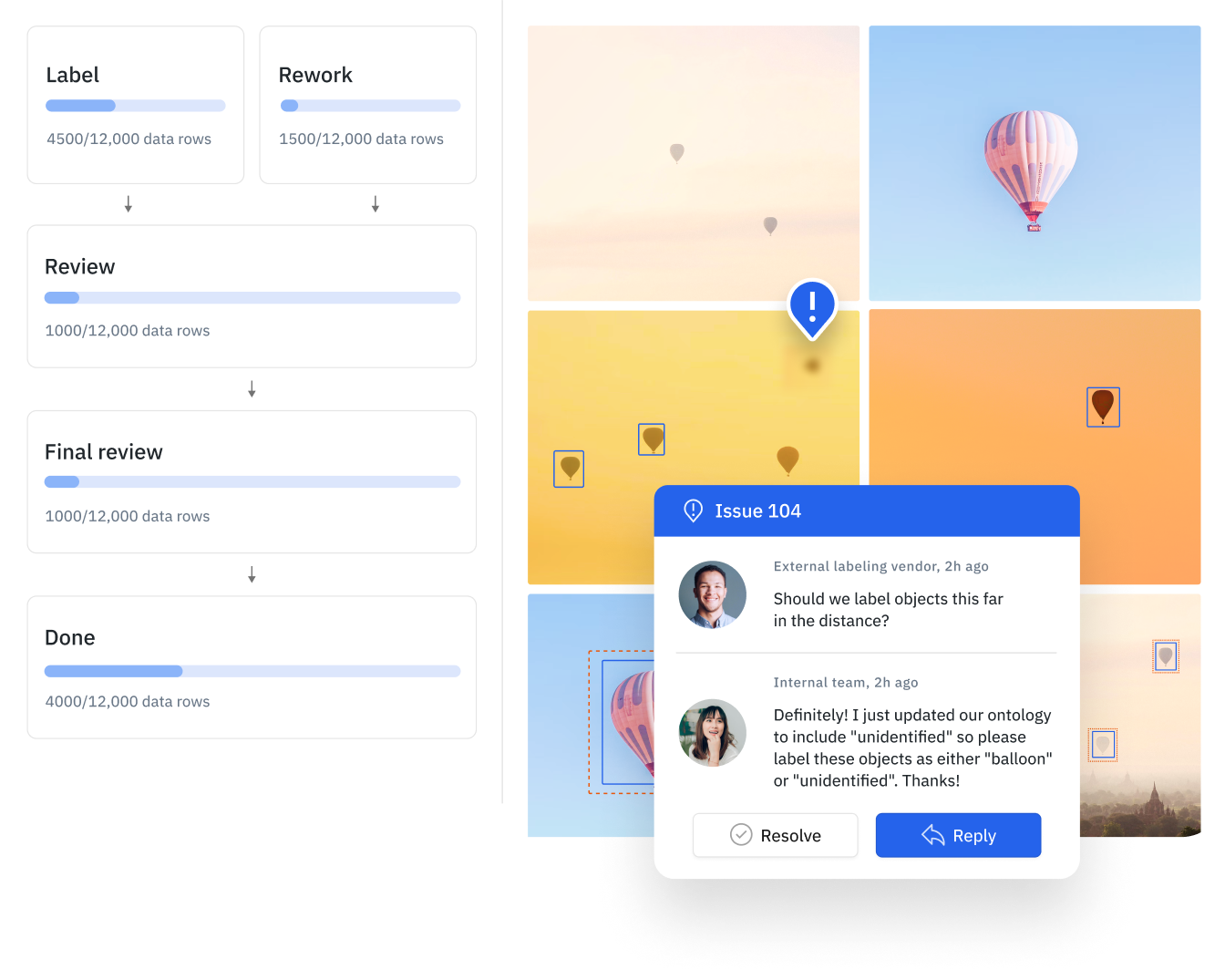
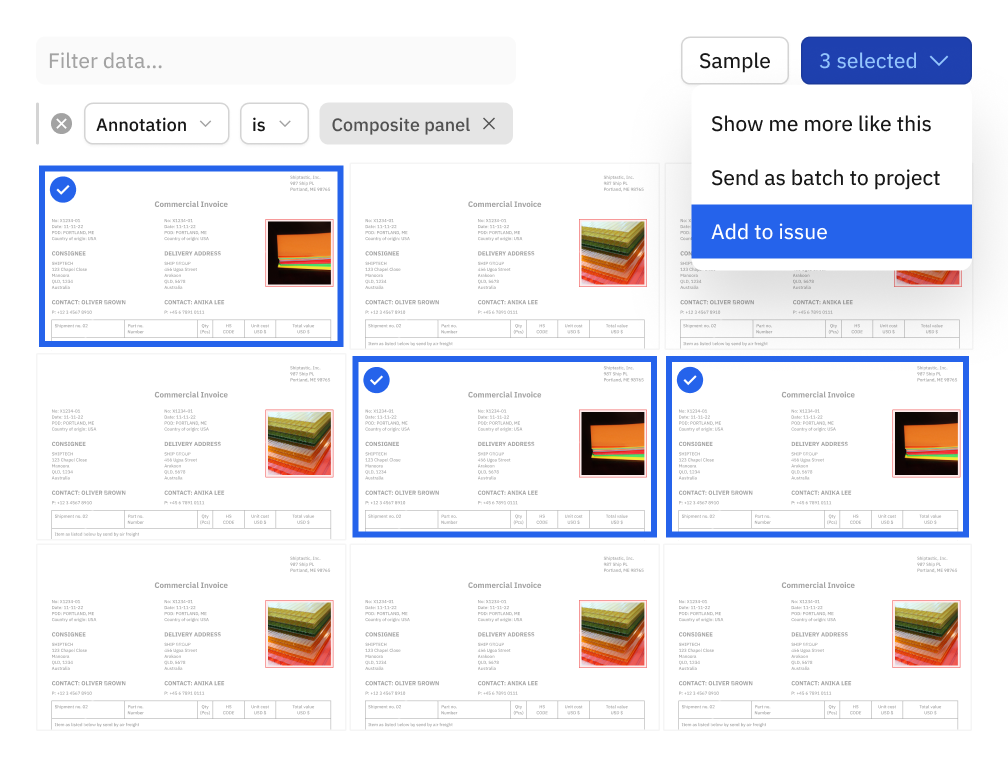
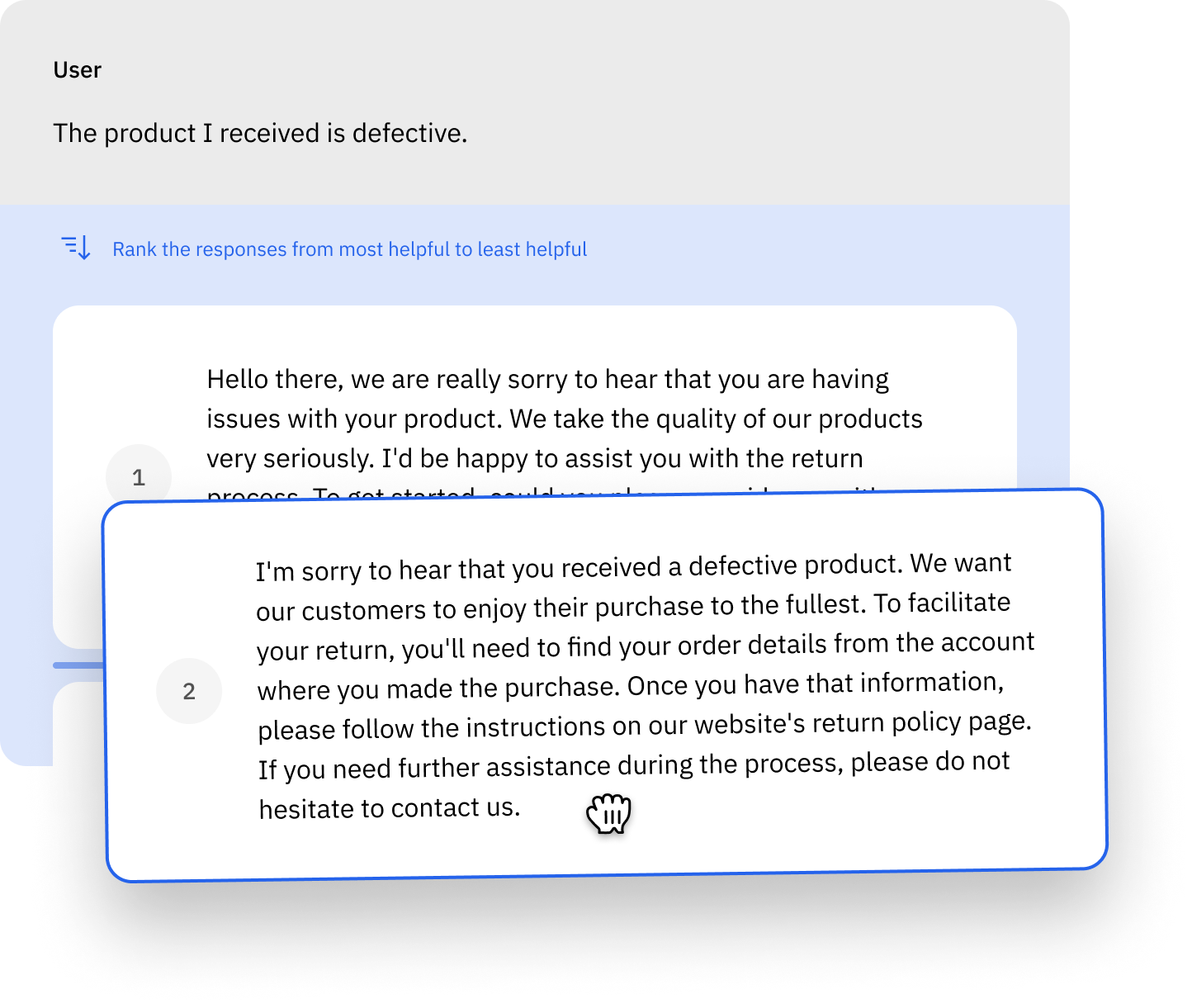
Reduce labeling time and spend by taking bulk action on these data rows — add metadata or bulk classify data rows and send them as pre-labels for human-in-the-loop review
Create a data curation pipeline to automatically surface and classify high-impact data based on specific parameters
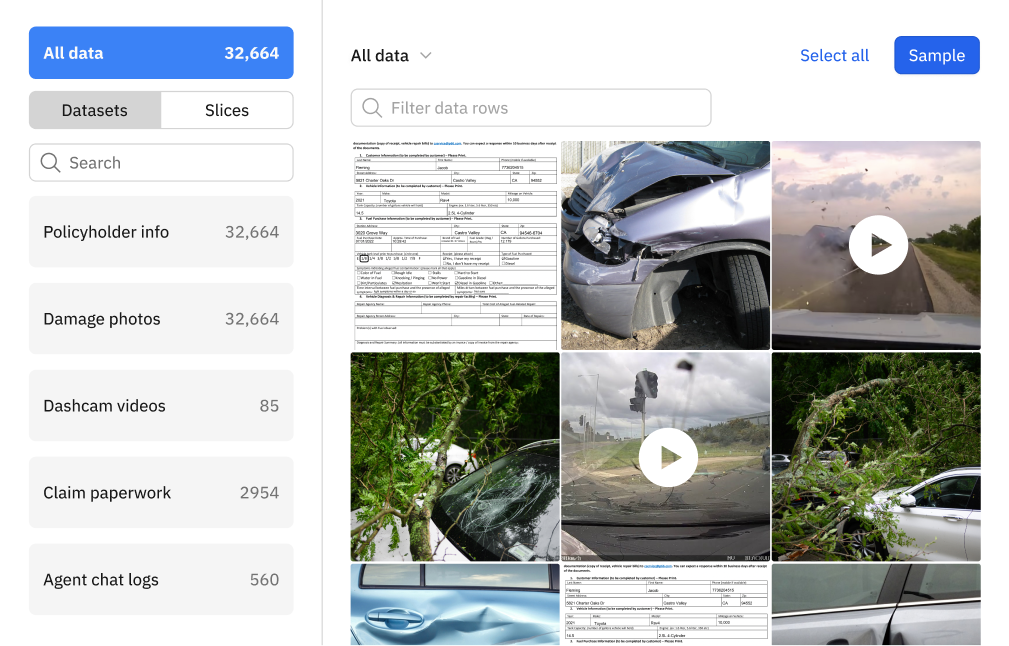
Get a centralized view of all your data
A single place to visualize, explore, and search for data:
Securely integrate Labelbox with an existing data store
Combine the best of vector search with traditional search capabilities
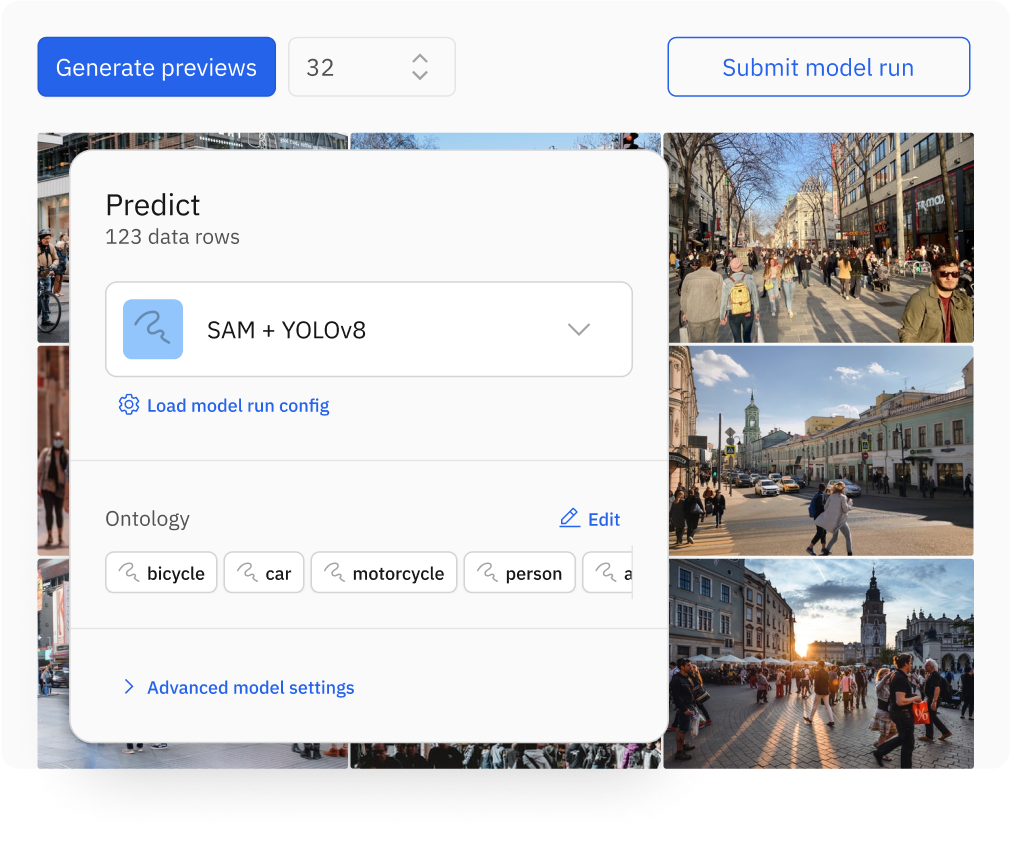
Launch downstream ML applications to improve model performance, send data to a labeling project, and more
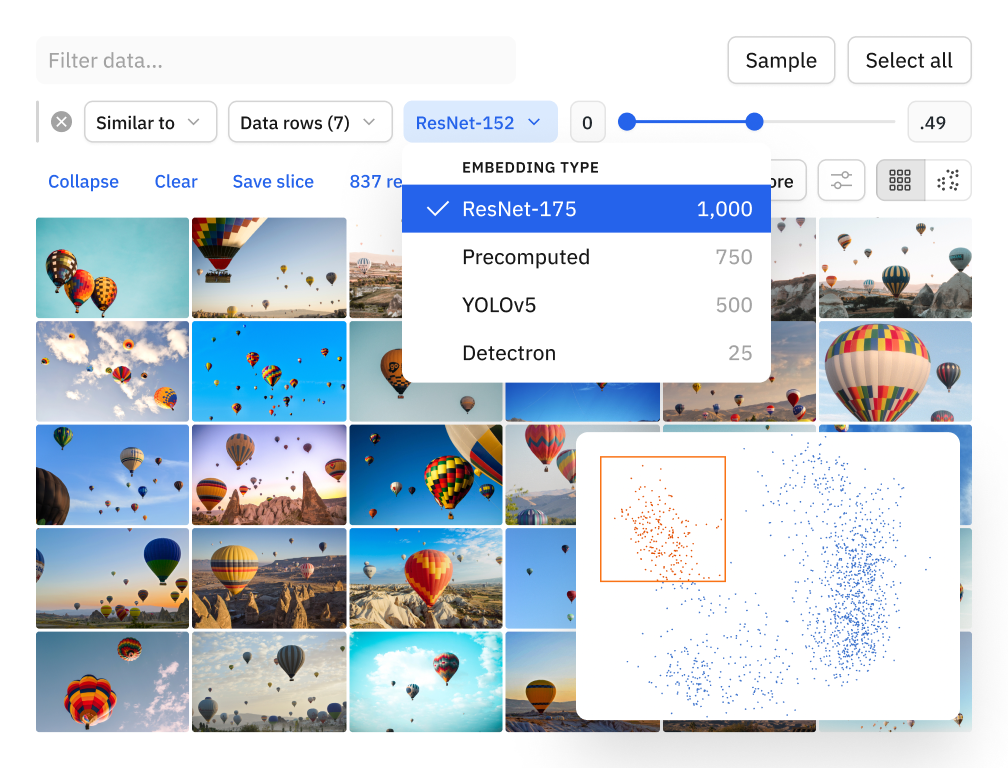
Cut data curation costs for AI in half
Surface high-impact data in your ever-growing data store and extract valuable insights:
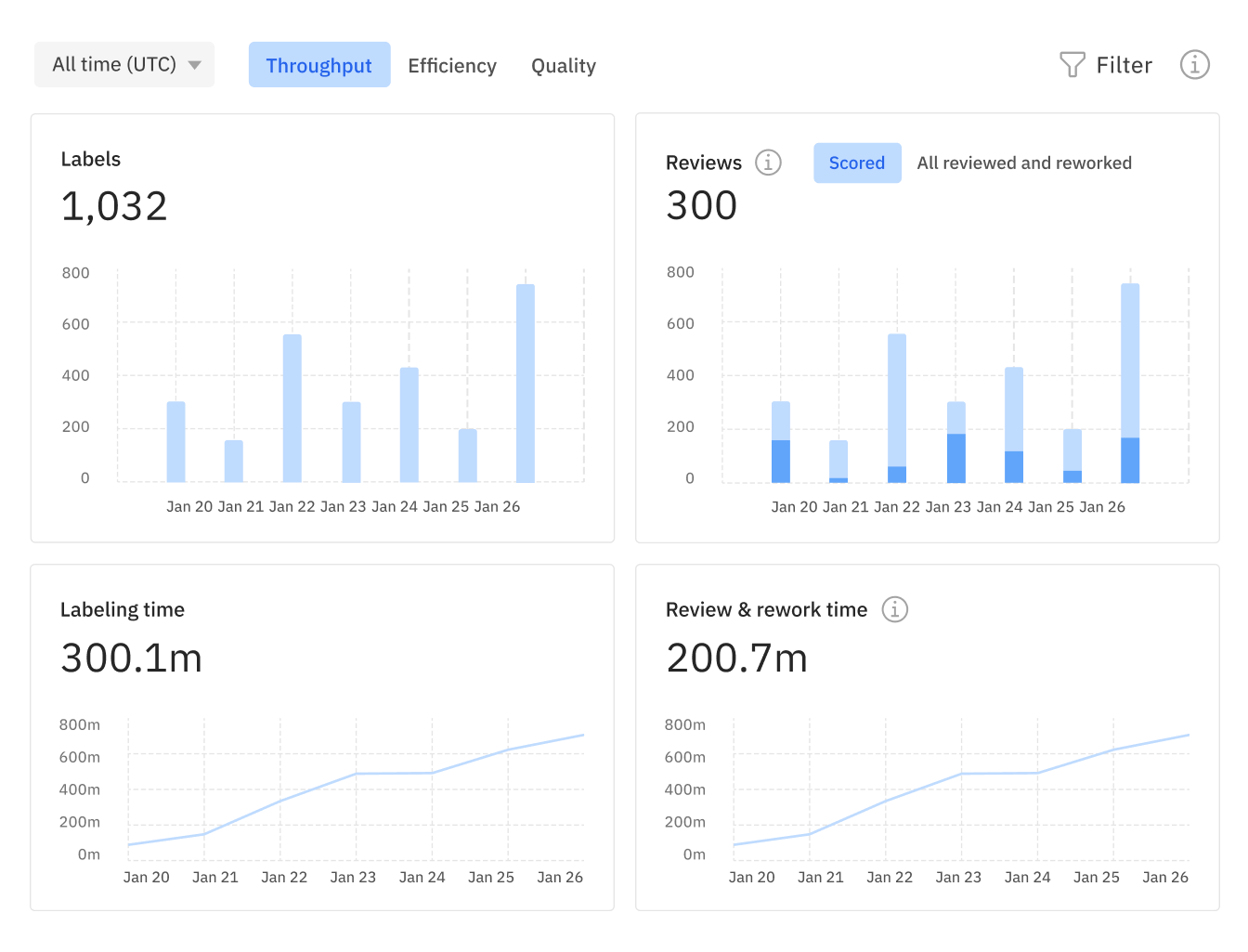
Leverage intuitive filters to instantly pinpoint relevant data containing specific attributes
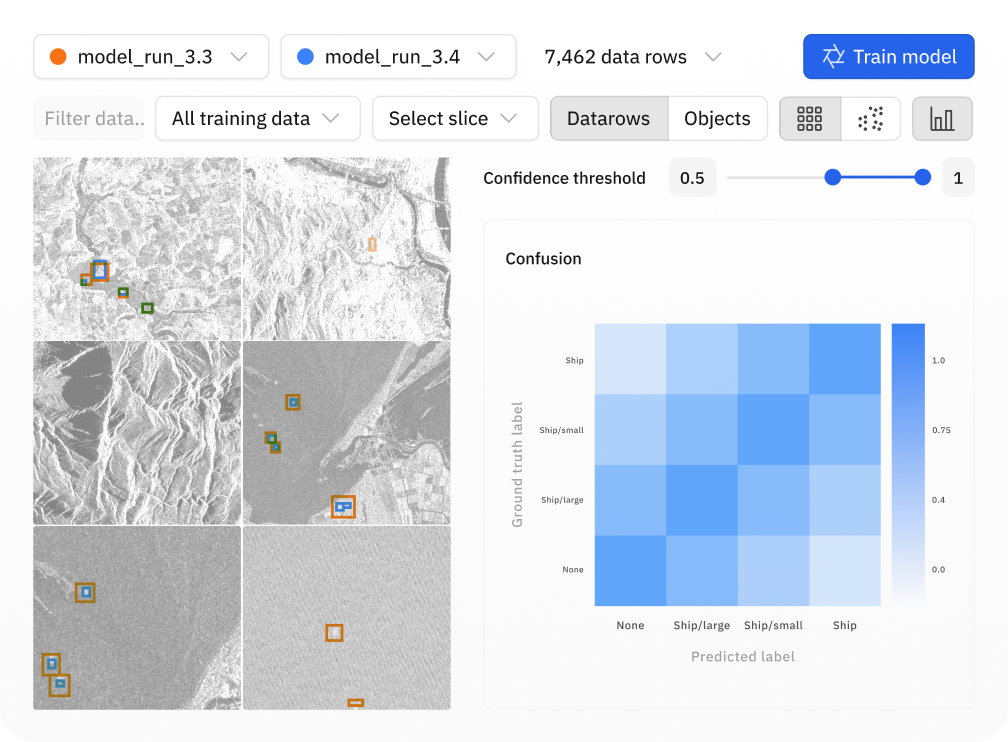
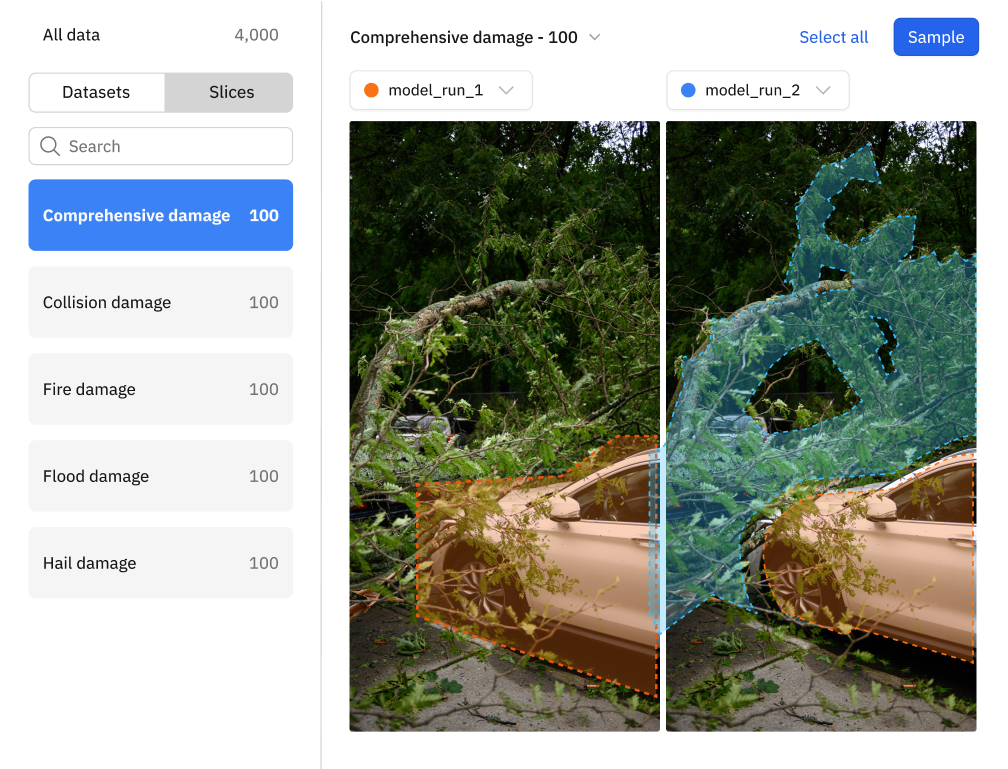
Create targeted data slices to unearth high-value examples, reveal trends, and analyze model performance on a subset of data
Combine semantic and vector searches to find similar data points within seconds

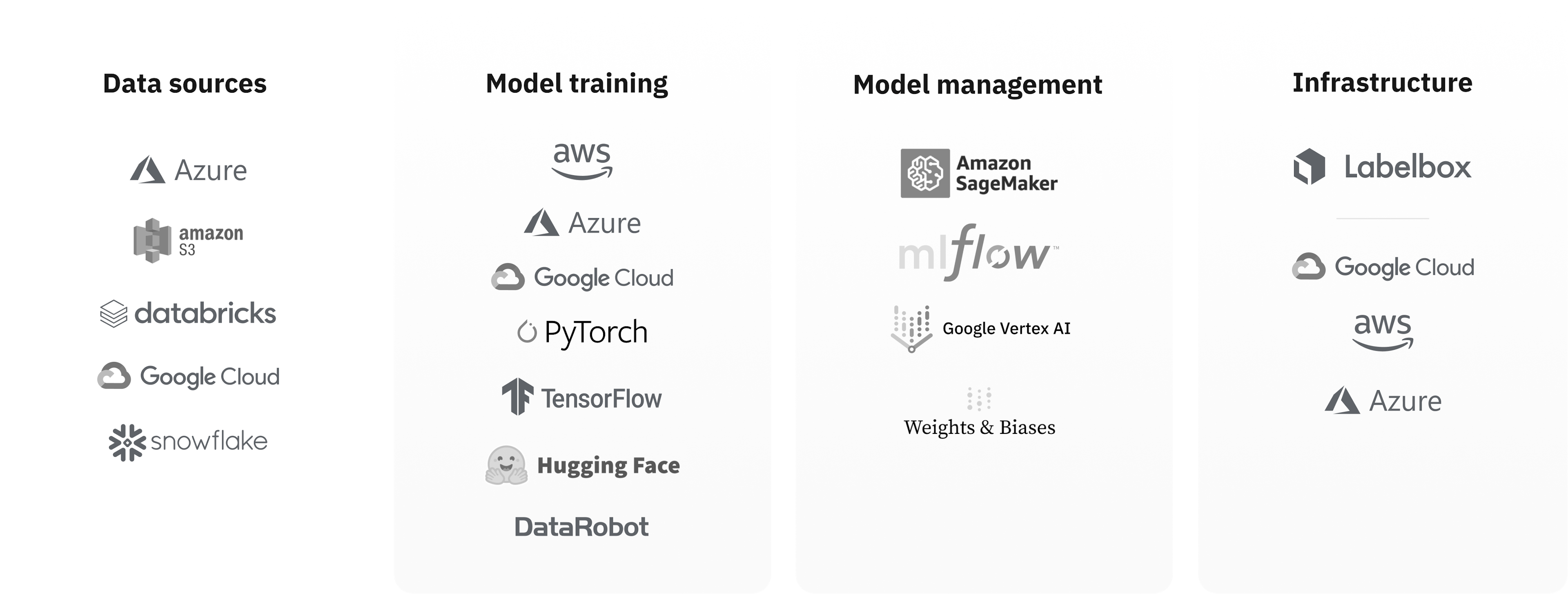
No-code integrations with 25+ popular data sources
Start with a production-grade AI data pipeline from day 1. Sync data from 25+ sources, including Google BigQuery, Amazon Redshift, Databricks, Snowflake & Elastic Search within minutes.
Learn more about