×![]()

 All guides
All guidesWhat is Model Distillation?

AI models are increasingly getting bigger with the increase in training data and the number of parameters. For instance, the latest Open AI’s GPT-4 model is estimated to have about 1.76 trillion parameters and terabytes of training corpus. Whether training large language models (LLMs) or neural networks, the main goal remains: to train using as much data as possible.
While training from diverse data and increasing the number of parameters produces powerful models, real-world application becomes challenging. Deploying larger and larger models to edge devices like mobile phones and smart devices becomes difficult because of their intensive computational requirements and costs.
To solve this challenge, model distillation comes in handy. Model distillation, also known as knowledge distillation, is a machine learning technique that involves transferring knowledge from a large model to a smaller one that can be deployed to production. It bridges the gap between computational demand and the cost of enormous models in the training lab and the real-world application of these models while maintaining performance.
Why Model Distillation?
Before diving into the steps taken to achieve model distillation, let’s discuss why it’s needed and the technical challenges it addresses in model training and deployment. Significant differences between requirements for model training and model inference stem from the infrastructure differences in training and deployment environments.
While LLMs like Llama and GPT-4 have incredible power, their applications suffer drawbacks caused by hardware requirements, speed, and cost. Hosting these models or directly accessing them through APIs would be expensive. The infrastructure cost and carbon footprints would be astronomical, even when run in the cloud. Large models also tend to be slow, which affects performance.
With model distillation, the deployment and real-world application of AI models can be realized. An inference-optimized model that keeps all the qualities and behaviors of the larger training model can be achieved. Using the teacher-student architecture, this supervised learning approach ensures knowledge transfer, enabling AI teams to develop secondary models that are responsive and cheaper to host and run.
How Does the Model Distillation Process Work?
The model distillation process can be complex, depending on the complexity of the base and target models. The key proponents are the teacher model, the knowledge, the student model, and the distillation algorithm. This model compression technique starts with the teacher model and ends with the optimization of the resultant model using the distillation loss function, as described in the steps below.
Teacher Model Training
The model distillation process starts with a pre-trained model, like an LLM trained on a large corpus. This phase involves selecting, fine-tuning, and/or training an expensive AI model with billions of parameters and gigabytes of data in a lab environment. The teacher model would be the base model in this case, serving as the knowledgeable expert system from which the knowledge is distilled. The student model would then inherit the behaviors and functionalities of this teacher model during knowledge transfer.
Soft targets are also generated during the training of the teacher model. Unlike hard labels, which are binary encoded, soft targets provide a more precise classification of the data points during the teacher training phase. The soft target generated offers more information on the teacher model’s decision-making, which will guide the student model's behavior during distillation.
Student Model Initialization
In this phase, a smaller and lightweight student model is introduced. The model is initialized with random weights and set ready for knowledge transfer, targeting deployability on edge devices. With a simpler architecture and shrank computational demands, this student model is trained to replicate the teacher model’s output probabilities.
Knowledge Transfer
After the student model is initialized, it is trained using the outputs of the teacher model in a process known as knowledge transfer; this is the distillation phase. Soft targets generated by the teacher model are combined with the original training dataset to train the student model. With the aim of matching the student and teacher’s predictions, the student model is steered towards mimicking the feature representation of the teacher model’s intermediate layers. In doing so, the student model learns the pairwise relation between data points captured by the base model. A distillation algorithm is applied in the knowledge transfer phase to ensure student models can acquire knowledge from the teacher model efficiently. Such algorithms include adversarial distillation, multi-teacher distillation, graph-based, and cross-modal distillation. The choice of these algorithms depends on the work at hand, the model’s features, and data points. Either way, applying a distillation knowledge algorithm is a highly encouraged practice during model distillation as it reduces complexity and improves the performance of the student model.
Optimization with Distillation Loss Function
As already highlighted, the learning curve is often steep for the student model, considering its minimal computation power and performance expectations. As a result, it might sometimes drift from the training domain, resulting in distillation loss. To address this challenge, a distillation loss function is applied to guide the knowledge transfer process. This loss function helps the student model to steadily acquire knowledge by quantifying the discrepancies between the teacher model’s soft targets and the student model’s predictions. These discrepancies provide a blueprint for minimizing feature activation differences between the teacher and student models, helping the student model to adapt gradually.
Fine-Tuning the Student Model
As much as the knowledge transfer process is expected to be seamless and the resultant model a replica of the teacher model, the student model might not achieve perfection. Therefore, it is a good practice to fine-tune the student model further on the original dataset after the model distillation process. This optional process employs supervised learning methodologies to improve the performance and accuracy of the student model.

What are the different types of Model Distillation?
Model distillation can be classified into three types: response-based, feature-based, and relation-based. Each type has a unique approach to knowledge transfer from the teacher model to the student model, as discussed below.
Response-based Model Distillation
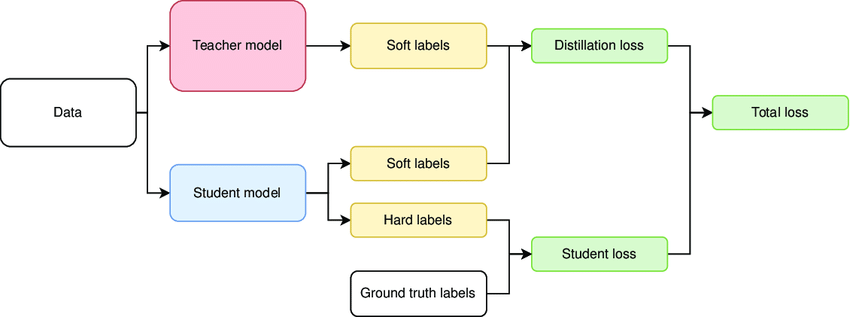
This is the most common and easiest-to-implement type of model distillation that relies on the teacher-model’s outputs. Instead of making primary predictions, the student model is trained to mimic the prediction of the teacher model. During the distillation process, the teacher model is prompted to generate soft labels. An algorithm is then applied to train the student model to predict the same soft labels as the teacher model and minimize the differences in their outputs (also know as distillation loss).
Feature-based Model Distillation
As the name suggests, feature-based distillation involves the student model learning from the teacher model’s internal features. In this type of model distillation, the teacher model is trained on task-specific features. The intermediate layers of these features are then extracted and used as targets when training student models. The student model is also trained to incrementally minimize the difference between the features it learns and those learned by the teacher model.

Relation-based Model Distillation
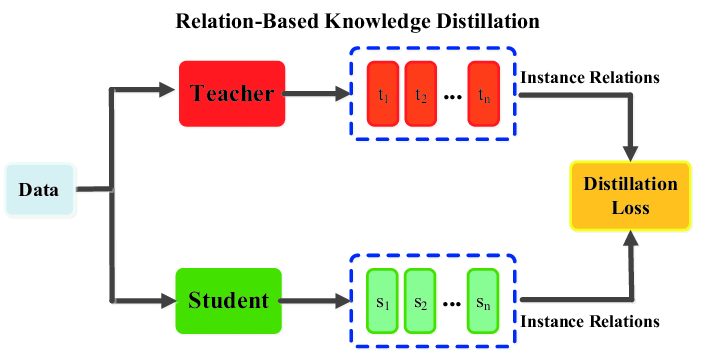
This is the most sophisticated yet robust type of model distillation. It focuses on transferring the underlying relationships between the inputs and outputs from the teacher model to the student model. The teacher model generates sets of relationship matrices for the input examples and output labels. While the goal is to minimize the loss function, the student model is trained on these relationship matrices progressively.
Model Distillation Schemes
Aside from the model distillation process and types, the technique applied during the student model training is also crucial. Depending on whether the teacher model is modified concurrently with the student model, there exist three primary model distillation schemes: offline, online, and self-distillation .
Offline Distillation
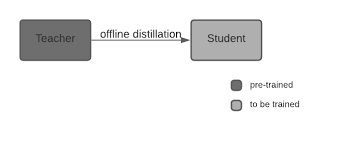
This is the most popular model distillation method, which involves pre-training a teacher model, freezing it, and later using it to train a student model. During the model distillation process, the training focuses on the student model as the teacher model remains unmodified.
Online Distillation
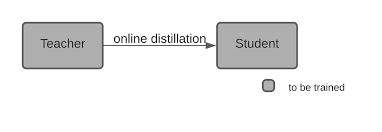
Online distillation is an end-to-end technique in which the student and teacher models are trained simultaneously. In other words, the teacher model is continuously updated with new datasets, and the student model is trained to reflect these changes.
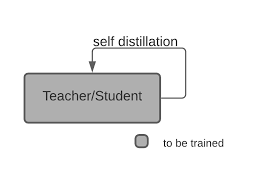
Self-Distillation
Self-distillation involves using the same networks for the teacher and student models. In this case, a model learns from itself, meaning knowledge from the deeper layers of the model is continuously distilled into its shallow section. This method solves the conventional limitations experienced when either online or offline techniques are used—the discrepancy in accuracy between teacher and student models.
Limitations of Model Distillation
Having looked at the benefits of model distillation, it’s important to discuss its limitations. While model distillation is a powerful knowledge transfer approach between models in different computational environments, it still suffers from various challenges:
- The technical complexities of the distillation process
- Difficulty in multi-task learning
- The student model is limited by the teacher
- Potential loss of information during the distillation process
- Limited applicability on existing proprietary models
Final Thoughts on Model Distillation
The AI models currently being rolled out are cumbersome and certainly not ideal for deployment straight from the lab. Model distillation provides an alternative model compression mechanism to train lightweight models with comparably lesser computational demands from these heavyweight teacher models. In the realm of artificial intelligence, this model training approach has proven helpful in bridging the gap between limited resources and high-performance capabilities of various AI models. Model distillation has limitless potential ahead as AI model training advances.
Labelbox aids in model distillation by providing a robust platform for generating high-quality labeled datasets, which are essential for both training the teacher model and fine-tuning the student model. With support for various data types and comprehensive management features, Labelbox also helps organize and version-control datasets, streamlining the process of integrating labeled data into the distillation pipeline. Try Labelbox for free to enhance the efficiency and effectiveness of the distillation process.